
Issue #29: How Data Platform Foundations Impact AI and ML Applications
Plus Current 2023 Conference Retrospectives, Apache Paimon: the Streaming Lakehouse and dbt Tests are expensive

Hello all, this week we have:
How Data Platform Foundations Impact AI and ML Applications
Current 2023 Conference Retrospectives
What is the Environmental Impact of Your Data? (Sponsored)
Beware of dbt Tests…. Your Money May Disappear
Pulumi Environments, Secrets, and Configuration
Why data integration will never be fully solved
How Data Platform Foundations Impact AI and ML Applications
I’ve always told my clients and colleagues that traditional rule-based software is difficult, but software containing Artificial Intelligence (AI) and/or Machine Learning (ML)* is even more difficult, sometimes impossible.
Why is this the case? Well, software is difficult because it’s like flying a plane while building it at the same time, but because AI and ML make rules on the fly based on various factors like training data, it’s like trying to build a plane in flight, but some parts of the plane will be designed by a machine, and you have little idea what that is going to look like till the machine finishes.
This double goes for more cutting-edge AI models like GPT, where only the creators of the software have a vague idea of what it will output.
This makes software with AI / ML more of a scientific experiment than engineering, which is going to make your project manager lose their mind when you have little idea how long a task is going to take.
But what will make everyone’s lives easier is having solid data foundations to work from. Learn to walk before running.
This isn’t a new concept; it’s just more relevant in a new AI hype cycle. Previous AI and ML hype cycles gave birth to the idea that good AI, ML, and advanced analytics are best made on top of high-quality, well-modeled, and governed data:
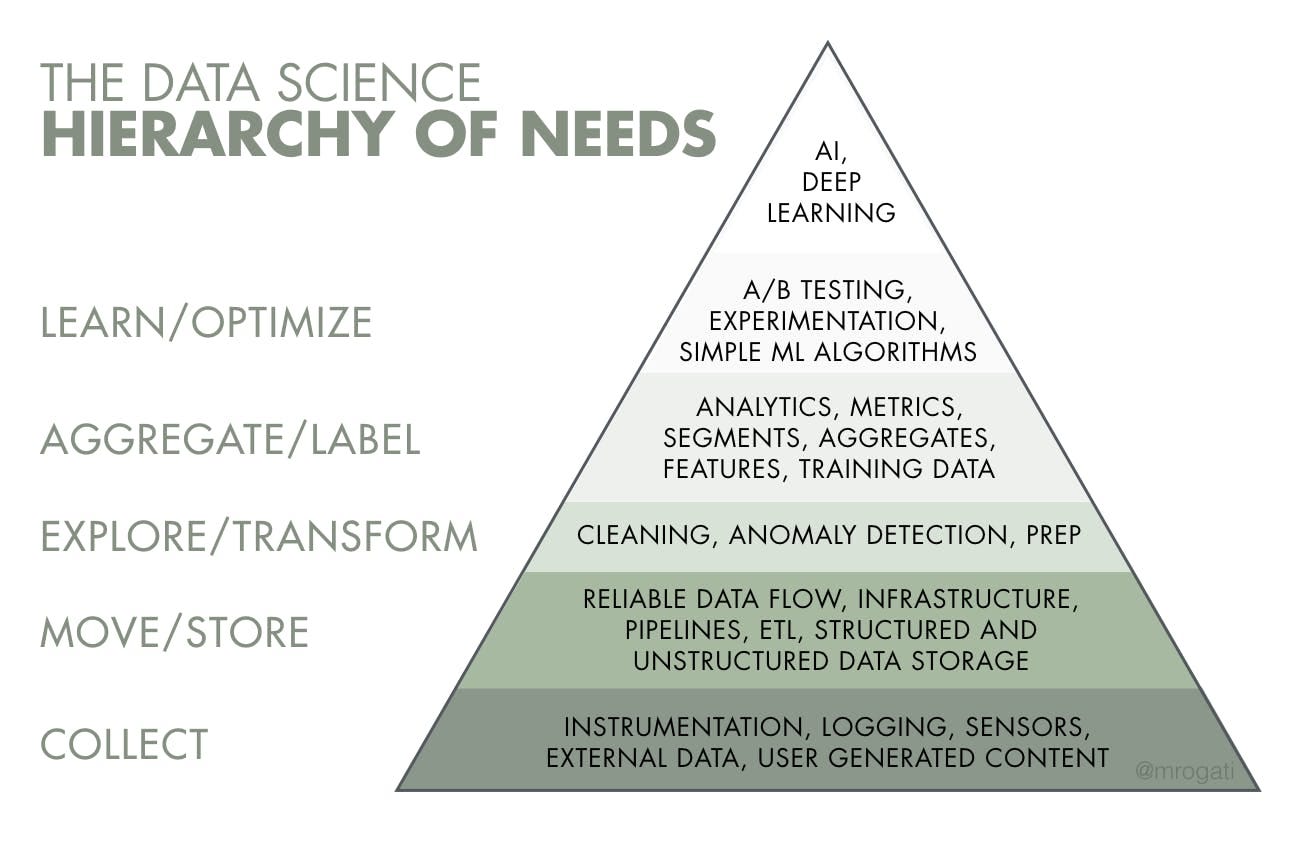
The above pyramid is from an article in 2017 and could arguably be said to be a reworking of the DKIW pyramid, which can trace it’s origins back to the 1920s.

.png")
So wisdom, making the best decisions, is based on learning from past decisions, which in this context means you’ll have great decision-making capability using AI and ML if you invest in your historical data processing beforehand.
But you probably did not click the link to this post for a history lesson; you want to make great AI and ML applications and want some tips to make that happen. So let’s get started. What platform foundations do you need?
Data Quality
If half your training data has wrong or no value, then it is likely to be half as accurate.
Studies show you’ll often get more accurate forecasts by increasing Data Quality than by using a bigger and more expensive model.
Also Data Quality tests tell Data Scientists what data is useable and inform them that data has drifted, potentially saving time and money in finding that out.
Data Modelling
As the grand sage of data, Joe Reis, says, Data Modelling is more important than ever in the age of Gen AI, as you cannot use Gen AI on your own data well without sufficient modelling to make it consistent, understandable, and easily readable.
Also, if done carefully, clean, deduped, and conformed data can save weeks or even months of work for Data Scientists.
Preferably, you’ll want data not to be overwritten when conformed and curated; forecasting looks at all changes over time, otherwise, if there are any important changes missing due overwritten data, you are going to have less accurate forecasts
Also, using aggregated and sometimes anonymized data can make your models less accurate, as you have less training data to work with.
You might think then, “I’ll go straight to the raw data”. Oh, sweet summer child, expect to lose months of time trying to replicate work already done for Business Intelligence (BI) to clean data and build business-critical metrics.
Try to weigh the trade-offs here between using raw and curated data for Data Science.
The curated layer will have less data to train on, but raw data will likely be more messy, harder to access, and have no business rules.
If you are heavily into ML/AI, you may want to invest in an append-only conformed middle layer of data (Data Vault, Activity Schema) if you haven’t already.
Classic AI/ML models generally prefer One Big Table (OBT) data models, which often expect one big table (or matrix) of features and target values. Though OBT models have their weaknesses, it’s not uncommon to use multiple model types. I cover this in more detail in my Data Modelling post.
Though Generative AI like GPT can take almost any data model, but smaller and cleaner model will likely give you more predictable results.
Data Governance
It’s easier to find the right or best data if it’s catalogued! Even a Data Dictionary of most organisational data in a spreadsheet will save days, if not weeks, and months of time for Data Scientists.
All applications involving data often have some legal and/or ethical concerns you need to be aware of. This is doubly true for most AI and ML applications, as they often make decisions that will impact people's lives. An experienced Data Governance team can often help you navigate these constantly changing legal waters so you don’t get hefty fines from your government.
If decision-making has large impact, you need to document your work
Black box models may be banned if you can’t show the ML or AI model how you came to a decision, which might be illegal or very risky in high-impact sectors (medicine).
I go into more depth on Data Governance here.
MLOps
While MLOps can use some different techniques and tools, you can save time if you already have a solid base of DataOps and/or DevOps expertise, services, and tools to rely on.
You’ll also want to track if you’re product is as efficient and trustworthy as possible, which is where DORA metrics like “time taken to complete a change“, “how many changes cause failures in production“ can help.
Business and Cultural Change
Have you time and budget to train people on the application? Have you communicated how the application will change the organisation?
How you use historical compared to AI/ML-created forecasting data requires different thinking for everyone that uses the application
It requires more “scientific” data analysis; how confident is the forecasting?
Cautionary Note
Having solid data foundations does not make building AI and ML applications easy - just a lot easier. You might have difficulty with having great data but not enough of it to train accurate enough models, for example.
Also, having a platform already in place does not mean no more modelling, re-architecture, and cataloguing needs to be done for AI and ML, but you should have to do far less of it if you already have a solid base.
Summary
There are a lot of elements to consider above, and I didn’t cover all the topics needed to deliver any successful AI/ML application, like working out the best business value or strategy, security implications, and effective team delivery.
Though if you have these foundations in place, typically found in a Data Platform, it can save you a lot of work on AI and ML applications and likely reduce your chance of failure too. It will also make your organisation better at reporting historical data, making it, in general, a more data-informed organisation.
Finally, I ask those exploring AI and ML projects to understand that while AI can bring big transformational change, be wary of buying into the hype too much: most of the AI and ML projects I’ve been on have been turned into more traditional rule-based projects, as we found out we only need cheaper rule-based software than a fancy, expensive model once digging into the requirements and data.
*There's an argument that most AI is just ML, which I’m somewhat partial to but is a well-covered topic elsewhere, so I’ll call it AI/ML and not digress here.
Current 2023 Conference Retrospectives
Current is a streaming/real-time conference hosted by Confluent, which sells arguably the most popular cloud-independent managed streaming product, based on open source Apache Kafka.
Because Confluent allows any vendor who is related to streaming to attend their event, even their competitors, it is probably the biggest streaming focus conference of the year.
The two big themes were:
Apache Flink, an open-source combined batch and streaming data analytics library that supports SQL, Python and Java APIs
Streaming Databases
Apache Flink
Apache Flink adoption has been growing quickly, and now Confluent has brought out a managed, serverless version of it with a demo at the conference. Yaroslav Tkachenko noted that it was disappointing that you could only use it in Confluent Cloud with no bring your own cloud option.
As mentioned in this newsletter before, Flink could soon become a common element in the data stack, with many vendors like AWS, Aiven and Ververica offering enterprise-ready versions of it now.
It will be interesting if we see other big vendors (Microsoft, Google, etc.) jump on the Flink bandwagon too.
Though it does suffer from some headwinds, it often requires Kafka to ingest data into it, and the cost of running both Kafka and Flink at the same time will not be cheap. Also, Databricks and Snowflake both offer streaming analytics now, which looks like an easier option for those not needing streaming first libraries like Flink or super low (sub-second) latencies.
Also, even though Flink has a SQL API, I don’t think it’s really suited for use in Data Analysis: it doesn’t have direct connectors for Power BI, Tableau, etc., and it doesn’t have much support for authentication and authorization options in the open source version. It’s more designed like Spark: only for transforming data, not serving it as well like a Lakehouse/Warehouse, so it requires pushing data elsewhere, likely via the Kafka connector.
Streaming Databases
While I think Streaming Database suffers from the similar headwinds as Flink, we are seeing a lot of new companies and investment in this sector, so this is one area to watch over the next few years.
Hubert Delay, author of Streaming Data Mesh and currently co-writing a book on the topic, explores the topic more.
What is the Environmental Impact of Your Data? (Sponsored)
GreenOps is a phrase already thrown around a lot, but expect to hear more of it: climate change is having a bigger impact on our lives every day, and governments are getting tighter on their emissions regulations.
My colleague Luke Sharma, who is Oakland’s resident expert on GreenOps and Green Data Strategies, gives tips and guidance on how to work towards a mature GreenOps process in your Data Strategy.
Beware of dbt Tests…. Your Money May Disappear
Paul Marcombes, Head of Data at Nickel, looks at the hidden costs of dbt tests, though I think they can apply to most kinds of Data Quality tests:
Data Quality is of course important, and keeping costs low is important, but Data Quality tests rarely come for free. So what do you do?
The difficult answer is to not run a complete set of tests and only run tests that bring the most value. It is a difficult answer, as there’s no silver bullet but a tradeoff between creating trustworthy data and staying on budget.
One thing worth also considering is looking at SQL constraints to replace some of your testing, which are sometimes called “free Data Quality tests“.
Finally, have a look at Data Quality libraries and products, as they can design their software to run their tests more efficiently than most custom code. I spoke to Soda CTO Tom Baeyens about this topic in our interview.
Pulumi Environments, Secrets, and Configuration
Managing environments and secrets can be a pain on any reasonably sized platform, as you’ll be storing configuration for multiple cloud accounts, not to mention 3rd party vendors as well.
But Pulumi, an Infrastructure as Code (IaC) and now Platform Engineering product, is now offering a feature to store all configurations and secrets in one place.
While Pulumi has a lot of work to do to knock Terraform from the IaC throne, I would seriously consider it for large, complex platforms.
Why data integration will never be fully solved
Very much onboard with this article, as no-code or low-code data integration solutions like Fivetran can get you far, but often not all the way, if you can afford them.
Anna Geller, Product Lead at Kestra, looks at open-source alternatives and their own tradeoffs.
Sponsored by The Oakland Group, a full-service data consultancy. Download our guide or contact us if you want to find out more about how we build Data Platforms!