
Issue #26: Team Topologies Book Review - Does it Work for Data Teams?
Plus: Data Governance is Broken, MDS Fest, The Streaming Plane, Intro to Data Vault Modelling and Finding the Right Balance in Data Mesh

Hi all, this week we have:
Small Book Review: Team Topologies
Data Governance is Broken
Modern Data Stack Festival 2023 Recap
The Streaming Plane
Practical Introduction to Data Vault Modelling
Finding the Right Balance in Data Mesh Implementations
Why AI Can’t Pass This Test
Small Book Review: Team Topologies
I read this book after Piethein Strengholt recommended it in his “Data Management at Scale“ book (which I also reviewed). It is authored by Matthew Skelton and Manuel Pais, both experienced consultants and trainers.
And in short, it’s a really great book for many IT leaders, especially those interested in implementing Data Products. It lays out a framework for creating teams that best fit the Agile and DevOps ways of working rather than trying to crowbar Agile in an existing organisation without any changes.
The authors are trying to ease the pain of engineers having to make many interactions and handoffs to get work done, which increases inefficiencies, burnout from too much context switching, issues caused by miscommunication, and therefore reduces employee engagement too.
This can happen in data by having a single cross-organisation team for:
Business Analysis
Data engineering
Data Science
Data Analysis
Data Architecture
Cloud Infrastructure
I could go on. This can create, as an example, several handoffs between teams to get a business requirement into an extra metric for a report.
What can also happen is Conway’s law (building software that reflects the organisation), instead of building software that matches the organisation’s value chains, which again can create unnecessary handoffs. The authors propose the opposite direction: ‘Inverse Conway Maneuver’ (ICM - building teams to match an organisation’s software services).
So we ideally want only one service to provide value to the organisation in a single, focused way (for example, a sales forecasting report) and with only one team entirely dedicated to making that service the best it can be. If we have multiple teams doing the above, it increases the number of handoffs needed, which in turn likely increases the number of miscommunications and misalignments too.
Doing the above will create a number of cross-functional stream-aligned, service, product, or feature teams, like:

And we’ll want to add a “Platform Team” for any central services like organisation-wide infrastructure, security, data governance, and monitoring:

There are also two other types of teams, called enabling teams and complicated-subsystem teams, which are specialised and less common but provide important cross-product, non-platform teams.
And if you want to see how this looks at scale, Docker has a blog on how they implement Team Topologies:

For those who already practise agile, this doesn’t look ground-breaking, and all I can say is that I had the same thought as someone who’s been working on cross-functional teams for many years now. But the authors here go into more depth about team design and interactions than I’ve seen elsewhere, so I still got a lot out of this book.
For example, thinking about and tracking all the interactions a team makes and then checking if they are the right interactions, the right number (too much equals burnout), and the right type of interactions. I also liked the idea of thinking about documenting team interactions like APIs - which made me think of Data Contracts or a standardised metadata model for a Data Product.
It’s quite easy to map this book to Data Products and Data Mesh and to be honest, I wouldn’t be surprised if Zhamak Dehghani was partly inspired by this book when creating the Data Mesh. And just like Data Mesh’s, I would say this team structure is best suited to larger, more decentralised Data Platforms.
Now, many experienced leaders fear a reorganisation because, at best, it reduces productivity and employee engagement in the short term as everyone adjusts to their new role and colleagues, and if done badly, it can leave permanent damage. The authors of this book are very open about this, saying their methods take time to work. So I’d understand if you read this book or review and thought, “This sounds great, but I don’t have time, money, or political clout to implement it.“.
I would say to that, yeah, this book is less useful to you and leaders of smaller teams, but still has many merits: you can still think about the interactions aspect in an existing team or re-think how best to collaborate on new projects and products where there are easier opportunities to create and redesign software teams.
Right, on to the links!
Data Governance is Broken
While I’m not sure I agree with the title of this article from Paolo Platter, CTO of Agile Lab, This is a good summary of issues that can happen in Data Governance: with a nod to my review above, look at all those handoffs and opportunities for miscommunication!
I also liked the recommendations for making it work better in organisations, especially the one about starting on governance as early as possible: governance is like cleaning the house; it’s easier and more efficient to do in lots of short bursts rather than in small amounts of big bursts of effort after rubbish has piled up.
I think the real issue with Data Governance is that, frankly, it doesn’t happen enough, especially at project or product inception. The same goes for Data Quality and Modelling. The reason why this happens is simple: in the very short term, governance doesn’t always bring value to a product, unlike, say, building another feature for a product like another set of charts for a report.
So governance problems like lack of documentation and data sharing pile up and get harder and harder to clean up as bad practises become habits (see my cleaning metaphor again).
The question for me is: should Data Governance (plus quality and modelling) be part of a Minimum Viable Product (MvP)? And if not, when should it be implemented?
Modern Data Stack Festival 2023
This was a great online conference hosted by Secoda two weeks ago, with talks and panels by Joe Reis, Taylor Brownlow, and Chad Sanderson.
So why am I linking to it now? Well, most of the videos have gone live for all to view:
You’ll likely find at least a few videos you’re interested in.
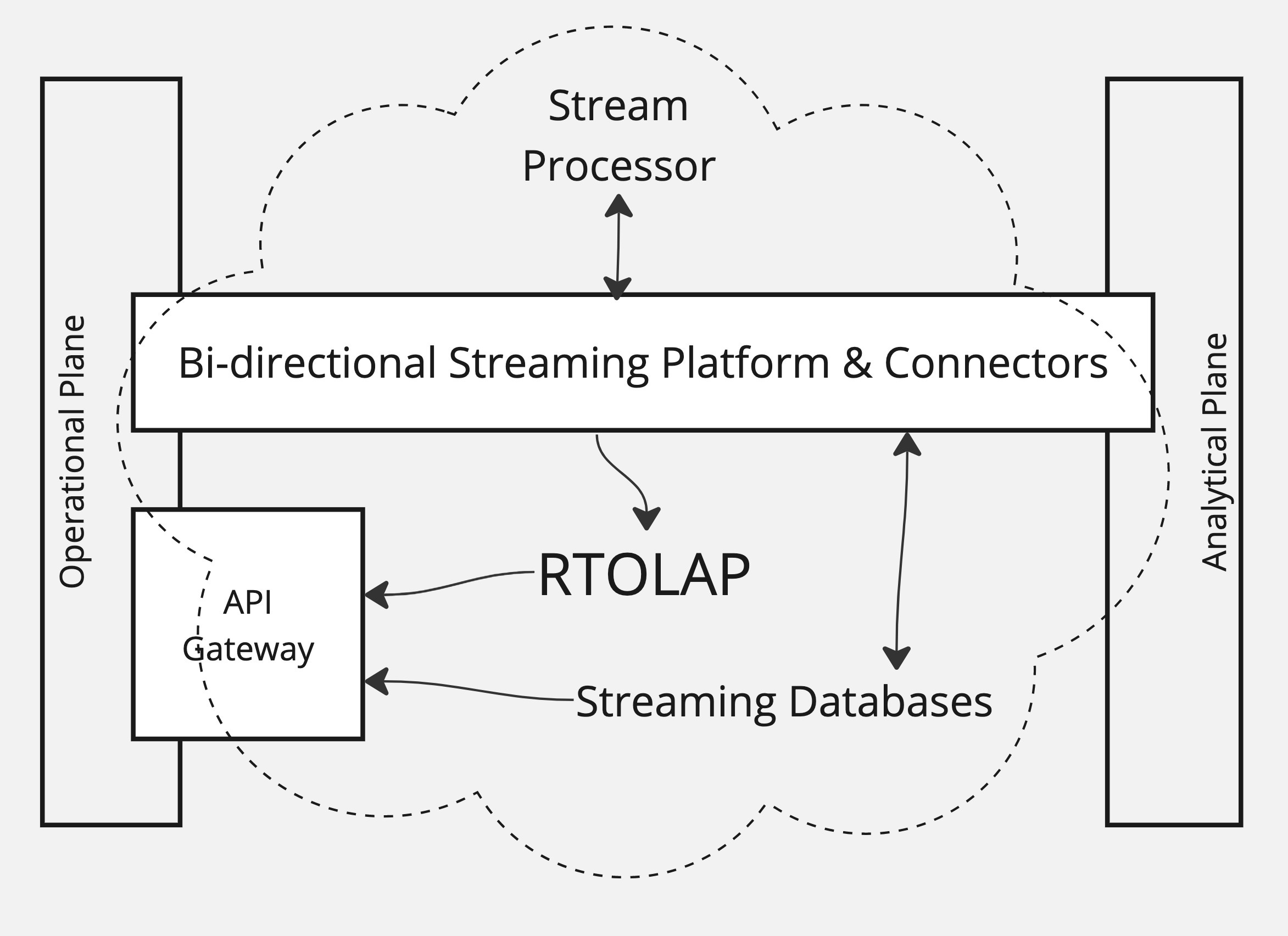
The Streaming Plane
The gap between operational data/application teams and data analytical teams has to be one of the most important issues today for Data Platforms, hence why Joe Reis has written not one but two articles on it.
Hubert Delay, co-author of the Streaming Data Mesh book, thinks the gap can be bridged with a Streaming Plane.
Practical Introduction to Data Vault Modelling
While I hear a lot of noise about data architects and engineers implementing Data Vaults, this is possibly the first time I’ve come across a good introduction to them that is not in a book or behind a paywall.
Not only that, Nuhad Shaabani has provided code to implement your own example Data Vault.
Finding the Right Balance: Socio-Technical Balance in Data Mesh Implementations
One of the benefits (and issues) of Data Mesh architecture is that it goes beyond technology and has solutions for how an organisation should structure it’s processes and teams. It’s not a technical architecture but a socio-technical architecture.
Omar Khawaja, Global Head of Data and Analytics at Givaudan, explains why socio-technical architectures are important and also breaks down the four core tenants of the Data Mesh into their social and technological parts to show what kind of effort is required for each of the tenants.
Why AI Can’t Pass This Test
While this is very much a video for a general audience, this video makes an important point: AI is currently great at certain things but hopeless at others. It can be easy to get caught up in the recent hype and think everything can be solved by GPT and similar models, but in reality, it’s best currently for a subset of tasks.
Sponsored by The Oakland Group, a full-service data consultancy. Download our guide or contact us if you want to find out more about how we build Data Platforms!