
Issue #24: Book Review of Data Management at Scale
Plus: Cloud Cost Management, DuckDB ADBC - 38x Better Performance Than ODBC, How to Check Two SQL Tables Are the Same and Comparing Open Source Soda with Great Expectations.

Hello all, this week we have:
Short Book Review: Data Management at Scale, 2nd Edition
Cloud Cost Management: How to Optimize and Control Cloud Expenses
Reviewing “Data Modeling with Snowflake”
Platform Engineering is Just DevOps with a Product Mindset
How to Check Two SQL Tables Are the Same
A Comparative Analysis of Open Source Data Quality Libraries: Great Expectations and Soda Core
DuckDB ADBC - 38x Better Performance Than ODBC
Now some bad news: I’m going to change my newsletter schedule to twice a week, so I can balance finishing off the guide and working on exciting new projects. I may still post weekly if there is a big news event and if my bandwidth increases.
Short Book Review: Data Management at Scale, 2nd Edition
I’ll start with a summary for busy readers: I highly recommend this book if you architect large Data Platforms or are just looking to get started in this area. It will give you a wealth of ideas and examples to use in practise while also mentioning their tradeoffs.
It is written by Piethein Strengholt, who is the Chief Data Officer of Microsoft Netherlands and a former Principal Architect at Dutch ban, ABN AMRO. He also has a great blog that I’d recommend reading if you’re interested in Data Mesh architectures and Azure.
While the book subtitle is “Modern Data Architecture with Data Mesh and Data Fabric“ and the book delivers that, by giving detail on both approaches and also spends a lot of time devoted to Data Products, so if you don’t believe in them, this probably isn’t the book for you.

The book does stray for a chapter or two outside analytical data: there is a chapter focusing on how data is created in the operational data plane and having a strong look at the pros and cons of Event Driven Architectures (EDA) which is an increasingly common architecture in large organisations and often has a large impact on how you analyse your data.
While some might think focusing on the operational data plane is a distraction and skip those sections, it does give you more insight into how data is created at scale.
Another aspect of the book I liked that it was not purely a technical architecture guide, it also covered constructing teams, processes, platform services, Master Data Management (MDM) and data governance which helps give a 360 view of Data Management.
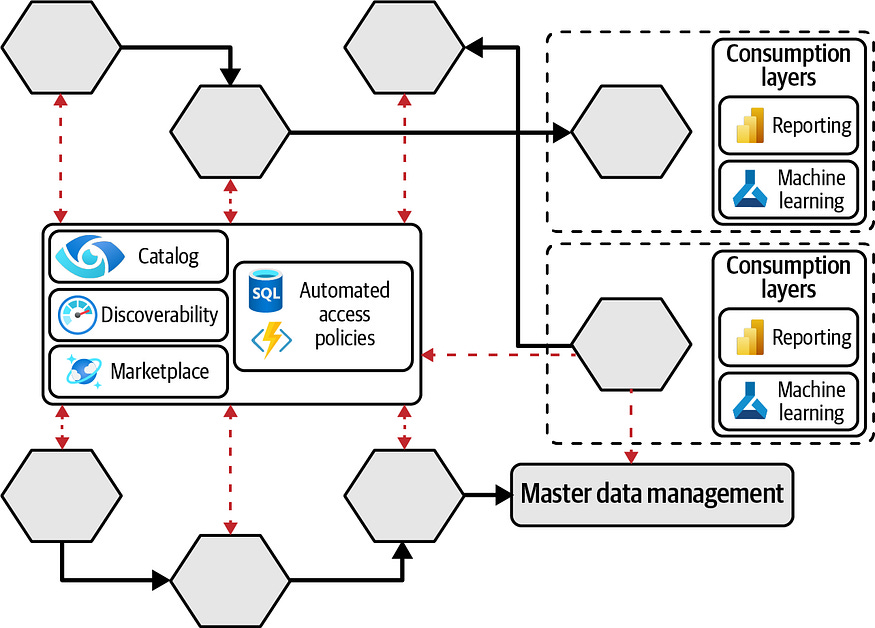
The only minor negative is all the architecture diagrams are drawn using Azure, Microsoft and Databricks components, though Piethein keeps his description of architectures fairly vendor neutral, so I feel confident AWS and GCP users can still get a lot of insight from this book.
I wouldn’t recommend making this your first book in data: I’d look instead at Joe Reis and Matt Housley’s excellent Fundamentals of Data Engineering and possibly read Zhamak Dehghani’s Data Mesh book, as Piethein doesn’t go into the details on why you’d might build a Data Mesh as much as Zhamark does.
Also, this is less useful if you run a small data team (3 to 6 people), as you’ll have little need to adapt to the scalable Data Platform patterns mentioned in this book, as Piethein says in one of his blogs:
“If your company has a lower level of data management maturity, a centralized approach in the beginning is more appropriate.”
Which I’d absolutely agree with.
Cloud Cost Management: How to Optimize and Control Cloud Expenses
Managing cloud costs is often a constant battle, especially during a period of high inflation, as costs are usually going up for running the same services while budgets stay flat.
Sonny Rivera, Senior Analytics Evangelist at ThoughtSpot, goes through some valuable tips to reduce cloud costs and also adds his thoughts on why managing cloud costs can be difficult.
I will also use this opportunity to shamelessly post that my colleague Jack Evans wrote a blog on managing cloud costs based on our many years of experience on this topic.
Reviewing “Data Modeling with Snowflake” by Serge Gershkovich
It’s been awhile since I’ve used Snowflake, so while I’ve seen this book get rave reviews, I haven’t had much time to read it myself. But here is one of those glowing reviews from Daan Bakboord, Managing Director Data & AI of Pong.
I’m also glad to see a modelling book focused on modern cloud data warehouses, which sometimes require thinking beyond just implementing another Kimball data model as warehouses like Snowflake operate very differently from regular database and can have different performance characteristics.
Platform engineering is just DevOps with a product mindset
A lot of the problems in data can come back to infrastructure and DevOps, as data can only move as fast and just important, change as fast, as the infrastructure it’s built on.
Luca Galante, Product at Platform Engineering company Humanitec, talks about the common issues in DevOps and infrastructure and how Platform Engineering could solve them.
Want more background on how to automate your data infrastructure? I wrote a section on it as part of my “How to Build a Data Platform“ guide a few weeks back.
How to Check Two SQL Tables Are the Same
Database PHD Student Remy Wang investigates how to compare two tables in a database, which isn’t quite as straight-forward as you might think it is.
Hacker News also has a great discussion on this, talking about what tooling you can use as well to compare tables.
I’ll also add my thoughts on this: where possible, compare numbers, not text, if you can, as text data is more likely to differ even though the content is the same due to different character encodings being used to create the data. It’s also often much slower to compare text than numbers.
A Comparative Analysis of Open Source Data Quality Libraries: Great Expectations and Soda Core
For fans of data quality content, Bruno Gonzalez has just started a newsletter dedicated to it, with one of their first posts doing a in-depth comparison of two of the most popular open-source data quality libraries.
My personal thoughts on this are: open-source Great Expectations has more features but is arguably harder to use than Soda CL and Soda has a more mature managed cloud version than Great Expectations (which is still in beta).
DuckDB ADBC - 38x Better Performance Than ODBC
This post is about how DuckDB, a analytical variant of SQLite (so a file-based analytical database) has now adopted a new type of connection driver, Arrow Database Connectivity (ADBC).
What is most interesting is the performance benchmark than blows ODBC out of the water:

Why does this matter? Most database connections with clients use ODBC/JDBC and I’ve configured connections using these drivers dozens of times in the past. Even if you don’t use ODBC/JDBC directly, it’s very likely you are using some kind of paid managed integration solution like Fivetran that uses the same drivers in a preconfigured connection.
So adopting ADBC may give you massive performance improvements when used with columnar database (DuckDB, Snowflake, …).
Sponsored by The Oakland Group, a full service data consultancy. Download our guide or contact us if you want to find out more about how we build Data Platforms!
I was excited to see Data Management at Scale getting the coverage it deserves. I especially enjoyed the use of DDD and how that fits into the Data space where it is often overlooked.