

Issue #23: Interview with Tom Baeyens, CTO of Data Quality Platform, Soda!
Issue #23: Interview with Tom Baeyens, CTO of Data Quality Platform, Soda!
Plus: Using Query Metadata to Improve Performance, Building a Real-Time Analytics Database, What Is Query Driven Data Modeling?, Reverse ETL 101 and AWS S3 Internals Deep Dive.

Hi all, something new this week by leading our newsletter with a interview with Tom Baeyens CTO of Soda. We discuss the Soda platform, common Data Quality issues and the future of Soda and Data Quality.
Plus, we have usual excellent set of videos and articles to share:
Starbursts Smart Indexing and Databricks Liquid Clustering - Using Query Metadata to Improve Performance
Building a Real-Time Analytics Database
What Is Query Driven Data Modeling?
What Are “Data Clean Rooms”?
Reverse ETL 101
Building and operating a pretty big storage system called S3
Tom Baeyens Interview
Jake: Hi Tom, would you like to introduce yourself?
Tom: I'm co-founder and CTO at Soda. I'm passionate about data. My common theme has been to build Domain-Specific Languages (DSL) that allow more people to automate their work. I've done this first on workflows and now in data quality.
I’ve also contributed heavily to open source: building software that is open source is not only good for business, it also helps the world become a better place.

Jake: How did the idea of building a Data Quality Platform come about?
Tom: We were working in the data management space. As more data became available, we realised that data quality was becoming the main bottleneck. New cloud -native data technologies also required new approaches to data quality.
Soda Platform
Jake: Could you give an overview of Soda and the challenges it solves?
Tom: Businesses increasingly thrive on analytical data. Soda helps companies prevent bad data from killing good business. Imagine the confusion in a board room when a report indicates business is going down and that there is doubt if the data is correct or not.
Another example is a recommendation engine that is trained on bad data and starts to recommend the wrong products. For large retail shops, recommendations can drive up to 35% of the revenue. It's easy to see that this has a major impact and large potential damages.
The way we help is by checking new data each time it is produced. Engineers as well as analysts can configure what must be checked in a declarative checks language. There is the ability for both automated and very explicit checks.
Jake: What makes Soda stand out from the competition?
Tom: The declarative language in which both engineers and analysts can express data quality checks. Many people in the organisation know and work with data, but often only a fraction of them know how to code in, say, Python. The SodaCL language is created so that all those people can contribute checks and keep the data in great shape.

Our tooling helps data teams take ownership and accept contributions from anyone in the organisation. A second unique aspect is that we have a built-in metric store that enables anomaly detection and other change over time thresholds for checks.

Jake: What is an ideal high-level workflow for using Soda in a Data Platform?
Engineers embed a Soda scan into the data producing workflow. The check files can be added to the existing git repository file structure. Engineers can add checks for all the assumptions they make for the correct operation of their pipelines, for example, schema, uniqueness or null checks. After that, analysts can propose checks to be added. If they can write SodaCL, they can do it self serve.
Analysts without software engineering skills can contribute data domain knowledge by asking engineers to add a SodaCL check for example: "In shops where the volume is greater than 10 million, all critical customers must have field technical contact filled in with a valid email address". Soda excels at bringing the producers and consumers together and allowing them to build out a decent suite of checks that prevents bad data.
Jake: The Soda documentation mentions you can integrate Soda throughout the Data Pipeline; could you give a high-level overview of how you use Soda at data ingestion, transformation, and serving?
Tom: The most common way to integrate Soda is by adding scans as steps to your orchestration job. A scan is a single execution of all checks related to the data produced in that pipeline. Right after ingestion is a very good place to run a first scan. And right before data is passed to consumers is another good point in the pipeline where a scan is appropriate. These two places provide a very good basis for proactively finding and later debugging data issues. If you want, you can go more fine grained, but we only see that in very data-mature organisations.

Jake: Soda now supports high-code with Python and low-code Data Quality checks with YAML. What are the use cases for both?
Tom: All checks are authored in SodaCL, which is a YAML based language. The execution of a scan can be coded in Python. That makes it very easy to embed scans anywhere in the pipeline and enables advanced features like setting custom variables.
Jake: What have been the most interesting and/or exciting use cases of Soda you've come across?
We've seen often that SodaCL is exposed to data consumers like analysts. They don't all have the skills to put code in production. But by deploying SodaCL checks, they can manage self-service. This removes a large part of the bottleneck for engineers that otherwise get constant requests to create or update checks programmatically.
Common Data Quality Implementation Issues
Jake: From personal experience, it can be hard to get investment in Data Quality until something goes badly wrong in the organisation. Do you have any advice to give on getting investment in proactive Data Quality efforts?
Tom: I think those times have changed. A few years back, we called this 'a compelling event': an data issue that got management exposure, leading to more awareness that data quality is important. Today, we see that almost all companies experience data issues regularly, and there is already much more awareness that data quality needs to be addressed as part of their day-to-day operations.
Jake: I've found in the past that extensive Quality checks can be expensive to run; how does Soda do anything to reduce this impact and/or have any thoughts to reduce the economic impact of DQ tests?
Tom: Great question, as I love to talk about this part. We spent a lot of effort optimising the load on warehouses to run data quality checks. It starts by leveraging the data inside the existing SQL engines, which prevents any unnecessary moving or copying data. But the crux is that Soda can process a large set of checks in a single scan. That allows for optimisations. Many checks are based on the same metrics. We ensure that those are only computed once. And the biggest cost reduction comes from merging many metrics into a single query.
By grouping metrics in the same query, we drastically reduce the number of passes that the warehouse has to make on the data. It's not the first part when explaining data quality and Soda, but a very important topic when adopting data quality at scale.
Note: Tom also mentioned he’s working on a article on this subject. I’ll add the link later when it’s uploaded.
Jake: Another issue I've come across is that I've seen organisations take a techno-centric approach to improving Data Quality, which can lead to poor adoption of Data Quality standards. Do you have any advice on this?
Tom: SodaCL has been designed exactly to cope with this. It's a compact DSL for engineers. That means that engineers can write advanced data quality checks in a few lines of SodaCL making them very productive. But at the same time, SodaCL is very readable and enables the more tech-savvy analysts to become self service. Self-serve authoring of checks with Soda Cloud goes beyond the engineering-only approach and opens up the data quality to more people, but all on the same foundation.
Future
Jake: What can we expect in the future from Soda in terms of features?
Tom: We are looking into applying data quality checks on streaming systems so that we can detect issues earlier in the pipelines.
Jake: Do you think this wave of generative AI technology will change how people approach Data Quality? If so, how?
Tom: Absolutely. Chatbots have been added in more and more applicable use cases. For data quality and SodaCL in particular, generative AI has proven a tremendous help for the many non-tech people that know the data domain. They can just use natural language to describe the check they want to build and our SodaGPT feature translates that into SodaCL checks. This expands checks authoring even further to include more people who have intimate knowledge about the data.
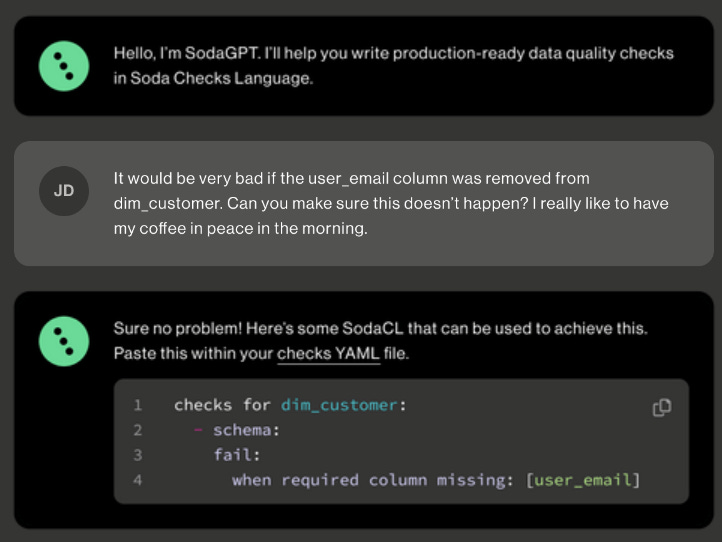
Jake: Finally, any trends do you think will emerge in data and/or Data Quality in the next one to two years?
Tom: Embedding data quality checks will become the most normal thing to do when building or changing data pipelines. The abnormal thing will be to skip that part.
We also believe that there will be a big change in how data ownership is handled. At the moment, it's really hard for engineers to take full ownership of the data they produce because they don't know all the details and guarantees of the data that they use as input to their pipelines. If producers upstream provide formal data contracts, then engineers can also take ownership of the full datasets they produce in their own pipelines. That's definitely a trend to watch out for.
Starbursts Smart Indexing and Databricks Liquid Clustering: Using Query Metadata to Improve Performance
Partitioning is a very popular technique to use on large datasets to save time and money on compute. It works by splitting up your datasets into files by columns that get filtered (WHERE clauses, etc.) most often by queries, so compute only has to read a subset of the data (say, the last 7 days of data, if partitioned by day) rather than scan all data.
Though they can be tricky to configure, as your query patterns on a dataset might change as the data and your business evolve. This is especially problematic as partitioning on columns that don’t get filtered often in queries can increase costs.
As a solution to this, Starburst has brought out “Smart Indexing” and Databricks “Liquid Clustering” within weeks of each other. They have different names but have the same rough idea: review the history of recent queries run on the dataset and build a partitioning/clustering strategy from that, so your partitioning strategy never goes out of date.
I suspect not everyone will need it, but pretty cool tech.

Building a Real-Time Analytics Database
This talk is another banger from the GOTO Conferences Youtube channel, albeit also a cleverly worked advert for StarTree by Vice President of Developer Relations, Tim Berglund: it takes the viewer through the decision making process of building a Real-Time Analytics Database in a Choose Your Own Adventure style, which made the video a fun and informative watch for anyone intrested in data, not just people interested in building or using Real-Time Analytics Database.
What Is Query Driven Data Modeling?
Another insightful article from Data Consultant SeattleDataGuy/Ben Rogojan again showing why he’s one of the more popular voices in Data Engineering.
Here, he has a balanced take on the relatively new practise of just coming up with a new data model, pipeline and dashboard when it is asked for by data consumers:

Now I’ve seen a lot of angry responses to this lack of Data Modelling, especially from Data Architects, as frankly, it outs them out of a job somewhat. Also, this style of modelling likely doesn’t work in regulated industries, especially banking, where it’s recommended to show the data lineage of your financial reports.
Can you imagine performing data lineage on thousands of pipelines, most of which were created to answer one question? Even if you use technology that can easily capture data lineage, it’s still likely to be expensive to perform and difficult to look through it all.
And that’s before mentioning how more expensive this all could be, as Ben calls out in his article.
However, there is something very agile, lean and “just in time” about this method: you’re doing just enough work to complete the task and no more. It will also be very appealing to industries like retail and advertising that need analytics in minutes or hours and not want to wait months or even years for a team of Data Architects to work out what data model they should have.
That said, if you do take this methodology, I’d recommend viewing it like a support function, where you hold frequent retrospectives to look at how you can improve the “time to insights” by pre building some tables or making analytical data more consistent, which requires, of course, Data Modelling.
What Are “Data Clean Rooms”?
While this article by Investigative Data Journalist Jon Keegan, is aimed at a more general audience, I felt it was still worth sharing as Data Clean Rooms solutions are everywhere (AWS, GCP, Snowflake, Databricks) these days and don’t think are well understood.
This article also asks “Why Are These Becoming More Popular?“ (legal requirements), “Are Clean Rooms a Silver Bullet?“ (no) and the numerous privacy concerns associated with using them.
Reverse ETL 101
I’ve written about Reverse ETL before, where you send data back to the applications / operational plane rather than out, but Madison Schott, author of The ABCs of Analytics Engineering, does a much deeper dive into the topic, especially focusing on how to use it with dbt.
Building and operating a pretty big storage system called S3
A monster 6k article from Andrew Warfield who is a Distinguished Engineer at Amazon, give insight into how S3 operates. Lots of great technical information here, but the most interesting points for me was how to manage people and yourself when working on such a large and complicated service.
Sponsored by The Oakland Group, a full service data consultancy. Download our guide or contact us if you want to find out more about how we build Data Platforms!