
Issue #22: What makes the Medallion Architecture Different?
Plus: Is Kimball Still Relevant?, Data Product Metadata Model Examples, World of CDC, You Can’t Master Data in a Database and Deep Dive into Distributed Architectures

This week has been a great week for high quality articles on data, I had to stop looking for more articles earlier than normal as I have a guide to finish. This week we have:
A short rant about the Medallion Architecture
Is Kimball Still Relevant?
Hello, World of CDC!
Grai: Open Source Data Lineage
You Can’t Master Data in a Database
Data Parallel, Task Parallel, and Agent Actor Architectures
Standardized Data Product Metadata Examples Based on Real-World Published Data Products
What makes the Medallion Architecture Different?
I’ve seen a few comments on social media about Medallion Architecture, saying it looks no different from the classic three-tier structure of Raw, Conformed and Enriched found in batch Data Warehouses and it’s just meaningless buzzwords created by Databricks to get more sweet Venture Capitalist money.

Could Databricks come up with less vague layer names than Gold, Silver and Bronze? Maybe, I suspect they wanted a set of names that doesn’t tie themselves to one modelling style, to show how flexible Medallion Architecture is (and sell more Databricks).
But it doesn’t change the fact Medallion Architecture does differ from other architectures.
What makes the architecture different is that Databricks supports both batch and streaming using the same technology across all three layers, whereas classic Batch, Lambda and Kappa Architectures have separate batch and real-time processing technologies.
This arguably makes it better than all of the above as it’s flexible in supporting streaming and batch while having lower maintenance than Lambda and Kappa as you only need one data processing product, not two (though you’d still keep the streaming and batch pipelines separate).
And just so it doesn’t look like I’m just shilling Databricks, this architecture can also be applied in Apache Flink and maybe Snowflake?, if Lakehouses are not your thing.
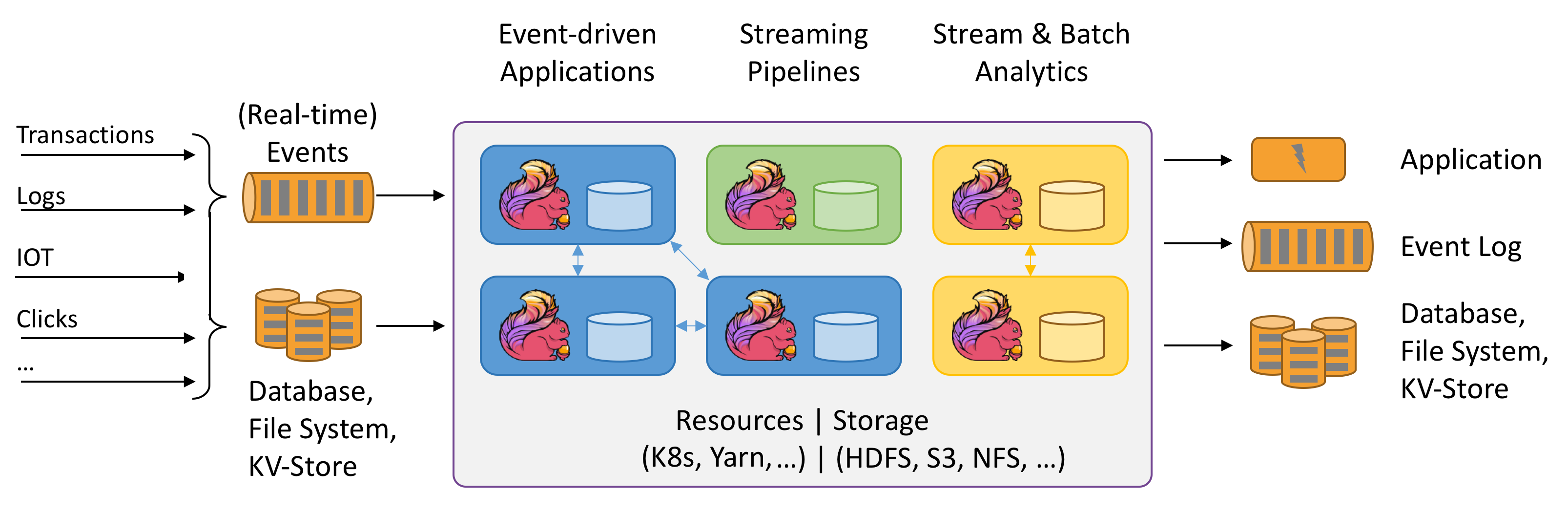
Though I will say if you’re doing no streaming processing, then yeah, it’s just classic batch processing.
Is Kimball Still Relevant?
Joe Reis, co-author of the excellent Fundamentals of Data Engineering book, woke up in a fiery mood on Friday:
Here’s the deal. If you’re aware of the various data modeling approaches and can pick the right approach for your particular situation, terrific. You’re a competent and thoughtful professional. To completely ignore data modeling is professionally negligent, and I’ll argue you’re unfit for your job. We can do better as an industry. Don’t burn down data modeling just yet…
I’m tempted to frame the above paragraph. The rest of the post is just as good.
I will add this though: while the world of Data Engineering (DE) may feel a bit lukewarm on Kimball models as there are some arguments it doesn't scale as well as Data Vault, Activity Schema or One Big Table, I feel Kimball is more in use than any other point in time due to being the default way to model data in Self-Service Business Intelligence applications (BI): Power BI and Tableau.
And BI is 10 times bigger in usage than DE, I say that as a DE myself.
Though if you hate the idea of Kimball models in your BI apps, I’d check out Narrator, which uses Activity Schema.
I think an argument can be made that we're living in an era where it is common in a large organisation to use multiple types of data models, whereas 15 to 30 years ago you could only use Kimball and you'd be called crazy to question it (though I could be wrong, I was still in school then!).
Hello, World of CDC!
I’ve covered Change Data Capture (CDC) in previous issues, but this three part series (so far) by Ryan Blue, former Senior Engineer at Netflix and now CEO of Tabular, goes arguably into more depth about implementing CDC, what issues you might run into and how to solve them.
Grai: Open Source Data Lineage
Grai is a new start-up offering Open Source Data Lineage with a cloud option. It also has features to show the downstream impact of failing Data Quality tests.
You Can’t Master Data in a Database
This is a great article on something that I’ve been thinking about for awhile: Master Data Management (MDM) / Customer 360 / Single View of the Customer should be done as close to the operational data processing as possible rather than implemented post import of data into an Analytical Storage.
You want to master data at the source, or as close as possible to the source so data duplicates have less impact than if data is exported to the analytical plane to be mastered. Steve Jones of Capgemini lists the above and many other reasons why MDM is the solution to a business operations problem and not an analytical data problem.
Though, I will argue that it can be hard to get this view across in a large organisation, so MDM ends up closer the analytical data because because that is where the most pain is felt of having no mastered data.
This article is also great and on a very similar theme, talking about putting MDM in the close to operational data in a Data Mesh context.
Data Parallel, Task Parallel, and Agent Actor Architectures
If you’re a big nerd like me and want to know how distributed data processing solutions like Spark, Flink and Ray work under the hood, this is the perfect article for you.
Zander Matheson, Konrad Sienkowski and Oli Makhasoeva of the Streaming Processing product, Bytewax, go through three common types of distributed compute, each of their pros & cons and what their use cases are.
Standardized Data Product Metadata Examples Based on Real-World Published Data Products
While there is a lot of talk about how Data Products in Data Mesh should have consistent metadata model across the organisation, we haven’t seen many examples shared in public, likely because organisations that adopted Data Products don’t want to share their meta-model for fear it would give away company secrets or increase security risks.
To help organisations figure out what metamodel their data products should contain, Jarkko Moilanen of API Economy Hacklab, has co-authored an open source specification with a few examples.
While the specification looks like a great starting point, I will say I don’t think this is the final say on the matter, as I would like more detail on the Data Quality section, including what tests are run.
Sponsored by The Oakland Group, a full service data consultancy. Download our guide or contact us if you want to find out more about how we build Data Platforms.
Thanks. Love the article.