
Issue #19: Databricks and Snowflake SUMMITGEDDON
Plus: Starburst Galaxy Launch, OpenMetadata reaches 1.0 and Polars CLI

It was a big week in data, with Databricks and Snowflake both announcing a raft of features as well as holding a three-day sales pitch/summit.
While there is lots of understandable cynicism about how aggressive both companies marketing is and debate on how useful these summits are to the average data professional, it’s still good to see there’s a lot of innovation in this space that will hopefully make our jobs easier. If you have a large data budget ;).
The one general thought I’ve had from the summits is that some of the features announced are outside the core of Databricks and Snowflake, which is to process lots of data quickly and reliably. Both companies have to be careful to keep their core propositions best in the market; otherwise, other companies will start to take their market share.
Databricks Summit
The Databricks Summit contained hundreds of talks on how to best use Databricks. There was a lot of announcements too and annoyingly, Databricks hasn’t put them all in one blog, so here is a list of ones that interested me the most:
The most exciting announcement to me was more Unity Catalog, because yes, I’m sad that I get most excited about Data Governance features.
I think strong Data Governance can make a organisation massively more efficient by making data discovery and debugging of data issues much easier. However, few organisations want to pay for a bespoke Data Catalog as it isn’t considered a “essential feature“ and often costs from £10k to £1m+, so Databricks giving all it’s customers Unity Catalog for sort of free* is a massive win for me.
I will say Unity Catalog is nowhere near as good as most bespoke Data Catalogs and is very locked into the Databricks ecosystem, but it’s better than nothing.
*Only available in premium tier, though from experience, most Databricks customers used premium anyway pre-Unity Catalog.
Lakehouse AI
With all the Large Learning Model (LLM) hype mostly caused by OpenAI’s GPT, Databricks has released a number of features to pitch itself as the place to build and customise LLMs.
I covered this last week.
Materialised Views and Streaming Tables for Databricks SQL
Materialised Views could be very useful for real-time Business Intelligence use cases and streaming integration with dbt is nice.
Delta Universal Format (UniForm)
Databricks Lakehouse file format, Delta Lake, will be able to be read by rival Iceberg and Hudi file formats, increasing interoperability.
Like every other data vendor, Databricks has added a service to query your data using prompts, which can generate SQL code and also help search for data and improve documentation.
One question I have with this and every similar LLM service is “Where does it send prompts and results?“. Often LLM service providers send prompts to an LLM model in the US, which isn’t good for European organisations that can’t allow company data to leave their country.
Snowflake Summit
Same deal as Databricks Summit: hundreds of talks on how to best use Snowflake, as well as a number of new features.
I feel Snowflake was living up to its sales pitch of creating a “Data Cloud“ by bringing services normally found in the big cloud providers:
Yes, Snowflake has created a container service, which is great if you wanted to build an app connected to Snowflake but didn’t want to learn how to use AWS ECS/Fargate, GCP Cloud Run or Azure Container Apps.
It is also a marketplace where you can use apps built by vendors. Some of the apps already released help enable LLMs, to help Snowflake pitch itself as the place to build and customise LLMs.
This container runs inside Snowflake sandbox, which probably means no or little networking shenanigans to deal with, to potentially a big time saver.
I also noticed Astronomer (managed Airflow), was one of the pre-built apps, that could make managing Airflow much easier.
The downside is that I’m pretty sure all major cloud container services are way more feature rich, have more support and are more customisable. Also it’s been fairly easy to deploy to these services for a number of years now.
I do say that as someone who been using Docker and Kubernetes for the past few years, so I expect someone who hasn’t done the learning curve I have to do on deploying containers to be more excited about this.
Snowflake’s ML-Powered Functions
Now you can have (limited) Machine Learning in your SQL.
Almost as good as native Snowflake table storage.
Extract Data from Unstructured Documents
I’m somewhat meh about it, especially if you can already use similar cloud services. Though it does look very easy to use. Like LakehouseIQ, I question where in the world it is sending the documents. Also, LakehouseIQ works on structured data too, unlike this.
Snowflake Supports GROUP BY ALL
This wasn’t mentioned in the summit, but might be the most exciting feature released: all other SQL dialects* ask you to type at every column you want to GROUP BY like a caveman, but Snowflake has added an ALL option.
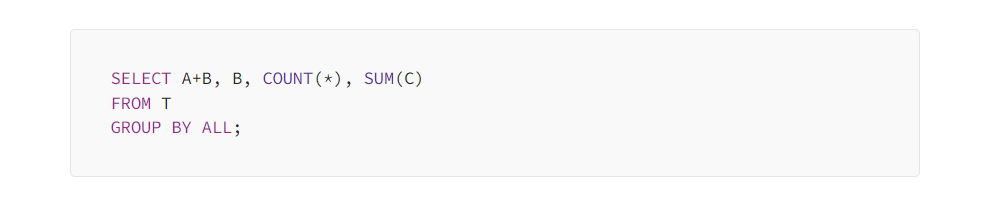
*Databricks / Spark also have this syntax.
Starburst Galaxy Launch Week
Starburst, for some crazy reason launched its managed service, Galaxy, only one week before Summitgeddon. They also launched Galaxy with lots of new feature announcements as well.
For those who don’t know, Starburst is enterprise Trino, an open source Lakehouse and federated query engine. Unlike most data processing engines, it isn’t tied to one storage format, so its supports 40+ data sources in the open source version and 50+ connectors in the Starburst version.
Starburst obviously saw my excitement for more Data Governance features in Lakehouses and released Gravity, a built-in Data Catalog for, I think, no extra cost on top of Galaxy. There is no data lineage like you can find in Unity Catalog, though it looks to have a stronger focus on metadata capture on attributes like Data Owners.
Other notable enterprise features announced were: row and column level security, abstraction of Lakehouse file formats and on average 40% better performance.
Oakland Data Governance Guide (Sponsored)
All this talk of Data Catalogs makes this a good shameless opportunity to talk up our experienced Data Governance team, who look to give clients a pathway to excellent, value-driven governance while trying to keep costs and disruptive business change down.
Click the link above for a guide on how you can deliver Data Governance through “Stealth“
OpenMetadata Release 1.0 - The Journey So Far
In the post above, OpenMetadata contributor Suresh Srinivas lists all the features OpenMetadata now has in version 1.0 and what to expect in the future.
OpenMetadata is an open source Data Catalog that differs from the competition by building an open standard for describing the metadata of a dataset.
It has now reached version 1.0 and become quite feature-rich, with enterprise security such as Single Sign On (SSO) and Role Based Access Control (RBAC) and the ability to import Data Quality test results via Great Expectations.
Polars CLI
So many product launches! Admittedly, this was so low-key I only found this after reading the Reddit post in r/rust.
Polars is a Rust library with a Python and JavaScript API that can query far more data than Pandas at much better speeds. It now has a CLI for when you don’t want to start up a Python program to quickly query some data.
It was through this that I discovered Polars also supports querying by SQL now as well.
Sponsored by The Oakland Group, a full service data consultancy.