
How to Build a Data Platform: Data Processing
Pros and Cons of Transactional Databases, Analytical Databases, Data Warehouses, Data Lakes and Data Lakehouse, Cluster vs Single Server Compute, Serverless vs. Dedicated and HTAP

Note, this is part of an in-progress guide on “How to Build a Data Platform”, subscribe for future updates:

Video
Introduction
How and where you process data is one of the most important decisions you’ll make when architecting a Data Platform, as it will enable/restrict what kind of features you can bring to your platform.
I would consider it the core of your Data Platform, so you generally pick your Data Processing solution and then build around that.
Transactional Databases
Transactional Databases are designed and normally used for handling lots of small reads and writes at once: from thousands to millions per second. Typical use case is tabular data storage for a website.
They can be used for analytical queries up to a point (1TB?) with some database performance tuning, and many data professionals still use them for data analysis as they are mature, feature-rich, and don’t have many downsides when processing small amounts of data.
Typically, Transactional Databases use fast hard drive storage located very close to the database server, which is great for fast response, but it is relatively expensive in large volumes, which makes them not very cost-effective for data analytics.
While it can be tempting to use the same database for both transactional and analytical workloads to save costs, it is usually better to split them so there no chance of them interfering with each other, plus it can give you better security by putting them on separate networks.
Examples of Transactional Databases are:
Analytical Databases
Analytical Databases are designed more for doing a smaller concurrent number of read and writes on larger datasets: they typically are only handling dozens or at most hundreds of connections but reading and writing data that is over 1TB in size.
Analytical Databases are often also called Data Warehouses, though this confusing naming as Data Warehouse is also somewhat of a tech-agnostic pattern that can also be applied to Data Lakehouses and Transactional Database.
Part of what often makes them better at analytical queries is they tend to store data in columns not rows, making it easier to retrieve and aggregate many rows of data but not single rows. They also tend to built on a distributed cluster of servers rather than a single server, which we talk about later.
Classically, Analytical Databases used hard drive storage, but modern Cloud Analytical Databases use cloud object storage like AWS S3 or Azure Data Lake, which has a slower response time, but cheaper so ideal for a small number of big long running queries (more than a few seconds).
These days Analytical Databases can not only query tabular data but also semi-structured data like JSON or XML, ingest streaming data, and even do (limited) Machine Learning.
Examples of Cloud Analytical Databases / Data Warehouses are:
But we’ve now seen a recent trend that every major Analytical Database is also a Data Lakehouse to a certain extent. But what is a Data Lakehouse?
Data Lakehouse
Data Lakehouses are evolution of Data Lakes: a collection of files and directories, usually in cloud object storage. Data Lakes can store any data that can be put in a file, can store files in deeply nested directories, are cheaper than hard drive storage, and can be queried by a variety of compute anywhere in the world.
But unlike Data Lakes, the files formats in a Lakehouse have transaction support, can update data without writing the whole file and can travel back in time to a earlier version. They are basically gained a lot of capabilities of a typical Database.
Data Lakehouses have similar performance to a Analytical Databases, but are more flexible, as the data can be processed and ingested data with more than one type of compute whereas database and data warehouse data storage typically can only use their own compute. This reduces lock-in and also possibly allows you to swap data processing engines to suit your needs.
Same applies too the other way round: you can queries a variety of data structures with same compute: a variety of tabular formats, semi-structured data (JSON, XML) and streaming data using the same data processing engine. We’ve heard some Data Professionals describe this as a “Headless Lakehouse“.
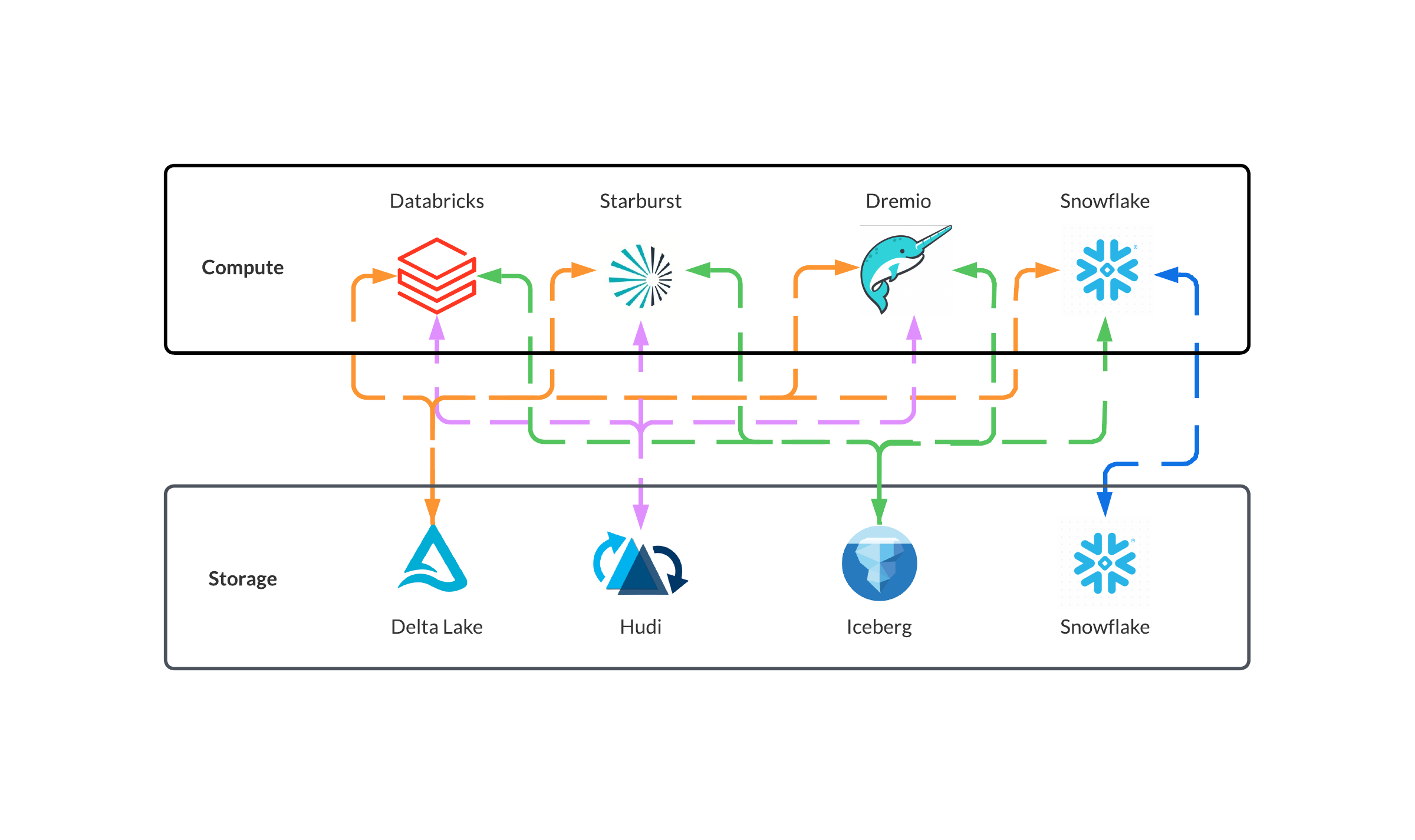
The cost is arguably reduced too, as Lakehouses use Cloud Object Storage (or a mix of object storage and hard drives), which is much cheaper than using only hard drives at the cost of having increased latency.
Lakehouses also often have Federated Querying, which allows them to easily join data from two different formats. This is great for data discovery, though in our experience often performance is worse than joining two datasets in the same format so is not a sliver bullet.
A new trend amongst Lakehouses is to have some Data Catalog capabilities with a small number of Data Governance features like Data Lineage to help manage your data at scale.
Examples of partly or wholly Data Lakehouses are:
The above just covers the compute part of a Lakehouse, as you can select a variety of file formats for the Lakehouse, we will list examples that allow for data transactions:
Lakehouses are often capable of reading directly many other file formats, such as Excel, CSV, JSON, Parquet and other databases, streaming services like Apache Kafka. Though Lakehouses often have the extra ability to read and write file partitions rather than the whole file for certain files like Parquet, to save on expensive data processing.
Distributed vs. Single Server Compute
Both Data Lakehouses and Analytical Databases typically have clusters of servers rather than a single one to process large volumes of data faster and guard against single server failures, but have latency overheads for each query caused by time to talk to each server in the cluster.
However, we may see a move away from clusters back to data analytics on single compute as the benefits of clusters for large datasets are not as big as they were 10 to 15 years ago.
Analytics on single compute tooling examples are DuckDB and Polars, both of which are very new, but could save you a lot of money and give better performance if you don’t need to select more than 100GB of data in one query.
Serverless vs. Dedicated
A lot the products above have a serverless and a dedicated options: serverless you only pay when you are actively using it, so cheaper if you have infrequent usage. Dedicated is cheaper if you are querying your warehouse more frequently (most hours in the day).
Also many serverless options have different / less features to their dedicated siblings: I recommend reading the fine print and limitations of serverless options before committing to them.
Hybrid Transactional and Analytical Processing (HTAP)
Why can’t you have a transactional and analytical on the same server?
Historically, this is partly due to fact the need different ways of storing to get the best performance, though there are some newer databases that do both workloads, called Hybrid Transactional and Analytical Processing (HTAP), with examples being Snowflake Unistore and GCP AlloyDB.
Having all data on the same server has obvious benefits: copying and moving data is much more performant than over a network and you have less maintenance overheads as you have less servers to manage.
However, there is a possibility of the two workloads interfering with each other, you lose a layer of security by not being able to put them on separate networks and operational and analytical teams will no longer have full control of their tech stack.
But That’s Not All…
Note we’re only cover a fraction of type of analytical storage and data processing tooling that are on offer, there are more niche databases that specialize in a subset of data analytics:
Graphs
Timeseries
Multi-model (document, graph, etc.)
In Memory
Real Time
And lots more (Real Time, Unstructured, Search, Vector, Accounting, etc.)
I think real time data processing deserves it’s own article due having different use cases, architecture and ecosystem. For those want a overview of the real time ecosystem, I recommend reading Hubert Delay’s four part series.
Summary
There is a lots of analytical data processing products to choose from to cover pretty much every niche and type of customer. It can be very expensive just to do a through analysis of what kind of data processing you need!
Lakehouses offer a bit more flexibility in allowing a wider variety of data that can read directly but you could argue Analytical Databases are bit easier to use if you use their native tightly coupled data format: you don’t have do any configuration (which isn’t much) to connect storage with compute.
You could argue there isn’t much difference between Analytical Databases and Lakehouse for the average user who is just writing SQL, with vendors trying to reach feature parity with one another even though the technology underneath is quite different.
Generally, architects of decentralised Data Platforms prefer Lakehouse’s flexibility, but it’s perfectly possibly to build a Data Mesh with Data Warehouses if you prefer.
You can use transactional databases for small to medium sized analytical queries in a pinch, though you’ll likely find better performance, more features devoted to analytics and possibly cost at larger data volumes.
Sponsored by The Oakland Group, a full service data consultancy. Download our guide or contact us if you want to find out more about how we build Data Platforms!